说明
本文以一个没有 Java 开发经验的运维角度从宏观上去理解 Hadoop 的云计算(也就是 MapReduce)框架模型的一些思想和运行流程;主要目的是在对 MapReduce 有一定了解后能用 Python 通过 streaming 工具来写 MapReduce。
MapReduce 工作流程
如下图所示:
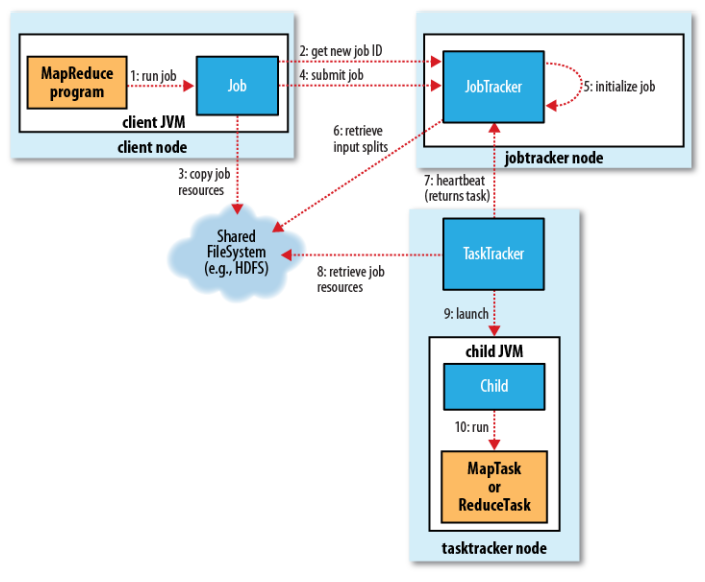
概括整个过程如下:
- 客户端启动一个作业;
- 客户端向 JobTracker 请求一个 job id;
- 客户端将运行作业所需的资源复制到 HDFS 上;
- 客户端将作业提交给 JobTracker;
- JobTracker 初始化作业对象,获取输入数据进行拆分作业;
- JobTracker 与 TaskTracker 保持心跳,将子作业下发给 TaskTracker;
- Tasktracker 从 HDFS 获取数据进行 MapTask 和 ReduceTask
具体的流程介绍可参考这篇文章或者《Hadoop 权威指南》
Shuffle 机制
Shuffle 意思是洗牌或搞乱,在整个 MapReduce 工作流程中 Shuffle 指的是 map 开始之后至 Reduce 完成之前的这个环节。理解其内部运行机制后,你会对那句形容 Shuffle 的话理解更深刻:排序是 Hadoop 的灵魂。
具体 Shuffle 的介绍参考这篇文章,好文,作者分析的通俗易懂,这里鄙人表示感谢。
MapReduce 数据流
理解数据流对写 MapReduce 很重要。总结来说就是:数据始终以 key/value 形式从 input 流向 output,在 input 端 map 有相应的转换方式定义如何将数据转换为 key/value 形式(针对我们这里说的以行计的日志,Hadoop 会将行的偏移量作为 key,以一行的实际内容作为 value),中间的 Shuffle 阶段也是针对 key 进行一个排序,尽可能的减少磁盘 IO 和网络带宽,最后的 output 段,reduce 程序也是以 key/value 形式输出结果到 HDFS。
具体数据流可大致参考这篇文章
用 Streaming 写 MapReduce
这里我用 Python 来写 map 和 recduce 程序,其他语言也类似。
mapper.py
#!/usr/bin/env python
import sys
hosts = ['221.176.86.150', '221.182.235.210', '221.182.238.74']
for line in sys.stdin:
line = line.strip()
segs = line.split('|')
if segs[1] in hosts:
print '%s;%s,%s' % (segs[1], segs[2], 1)reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_key = None
current_vlaue = 0
key = None
for line in sys.stdin:
line = line.strip()
segs = line.split(',', 1)
key = segs[0]
value = segs[1]
try:
value = int(value)
except ValueError:
continue
if current_key == key:
current_value += value
else:
if current_key:
print '%s,%s' % (current_key, current_value)
current_key = key
current_value= value
if current_key == key:
print '%s,%s' % (current_key, current_value)运行命令
hadoop jar
$HADOOP_HOME/contrib/streaming/hadoop-streaming-1.0.3.jar
-file /path/to/mapper.py -mapper /path/to/mapper.py
-file /path/to/reducer.py -reducer /path/to/reducer.py
-input /hadoop/path/*.gz
-output /hadoop/output/
-jobconf stream.non.zero.exit.is.failure=false
-jobconf stream.recordreader.compression=gzip说明:
- file 制定对应的 map 和 reduce 程序;
- input 制定 input 数据路径;
- output 制定 output 结果路径;
stream.non.zero.exit.is.failure=false避免程序返回值不为 0 导致的任务失败;stream.recordreader.compression=gzip指明处理的数据为压缩格式。